



响度与响度处理经验谈(下)游戏响度规划与量产控制

大多数时候,我们面临的声音是非常复杂的。在游戏里,每个独立声音的存在都是整体输出响度里的一份子。我们不可能像影视制作那样,随时根据需要来调整任何一个小片段的动态、频响等状态。所以这是个非常复杂的问题,想了很久都没想出来怎样一个思路可以把这事情说清楚。权且供各位争议一下吧。在这个问题上,每个有经验的设计师都会有自己的一套方法,其中有些手法是个人独特的,而有些是行业制定的一些基本标准。对于游戏来说,或许处理10个、100个样本还是很容易的,但是要平衡成千上万个样本的频响和响度,那就完全是另一件事情了。这就是艺术创作和量产的本质区别。
样本频响的控制,无论是何种类型的样本,即使是音乐和语音,都要为整体服务。所以,首先考虑的是让他们让出足够响度和频响給其他声音,这是响度控制的第一原则。 就拿音乐来说,原作一定是出版级别的全动态频响,而在游戏里,和电影一样,必须要让出足够空间,多数时候它不应该是全频段的。
目前单机领域普遍采用的样本RMS响度参考量如下:
- 音乐:-16dB
- 环境声:-16dB
- 语音: -12dB
- In-game音效: -16dB
- UI: -16dB
(以上所有峰值都不超过-3dB,每种声音的RMS大约有上下2dB的允许差距空间)
通常的样本音量与FMOD音量设定如下:
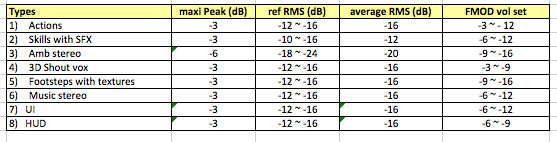
在这个体系下,对应的常见流程是:
- 首先为一个游戏设定一个音量参照系。“音量参照”往往意味着,这种声音的音量始终作为整体音量的上限,只允许某些时候其他少部分声音等于或者略大于这个参考音量。大多数情况,选择的是对白(不是呼喝声)。有些设计师根据项目实际情况,也会选择音乐甚至UI作为音量参照。
- 同一种类型的样本,无论如何播放、它用来做什么,都会确保它们的RMS响度接近对应的数值。也就是说,除了语音,其他样本的RMS都是在-16dB左右。
- 在游戏中,这些声音的音量平衡,基本上要通过SoundEvent或者SoundCue的音量参数、Roll-off参数等进行。如此,你在平衡调整的时候才能有一个明确的“响”还是“轻的指标。
- 而色彩、频响方面的层次考量,往往实在项目中后期、至少80%的主要资源都进入游戏后,才开始对不同功能的样本再进行优化和渲染。其中主要是声音的景深和频响。随后再调整sound event volume。
这种处理响度和平衡的的思路,首先是把单个样本控制在一个相对稳定的量级上,随后通过逻辑来控制和平衡整体输出的响度。这种“传统”的平衡手法是有相当充足的道理的,也是基于商业影视和音乐领域多年来积累的混音经验。这种平衡的方式是以静态混音为主,辅助以一定程度的动态混音。原则上,动态混音平衡也并不是作为主要的和根本的手法,尤其在项目中前期阶段。这种做法的直接好处就是:任何阶段,无论样本还是Event Volume体系里,都会有明确的音量标准让你很容易去判断。当然,这种思路也存在一个比较大的问题:入门的门槛比较高,需要设计师有非常好的混音训练基础和听力基础。
应该说,这也是目前单机领域的主流做法,并且由于近几年更多影视职业背景的专业人士转入游戏领域,这种思路得到了更深的发展。目前的引擎也越来越需要设计师具备这样的思路。天刀就是个很有意思的例子。当我接手的时候,我做的第一件事情是:
- 把每一种类型(分类)的声音样本都快速浏览一遍,有些时候我是有重点地随机抽取。比如说技能打击和基本身体动作作为一组、呼喝语音和台词语音作为一组、战斗音乐和纯背景音乐作为一组。我要看的是这些样本在各分类组中的平均响度和基本响度差范围。
- 理解这些类型的声音在FMOD里音量参数的设定情况,以及通过一些参数和样本修改实验来建立我对这个引擎里的音量实时计算和样本之间的关系。(有意思的是,每个引擎、甚至同一个引擎的不同版本,在这个问题上都会差异很大!对我而言抓到其中的微妙关系是一件非常刺激的烧脑运动:-)。
简而言之:我要在样本RMS值、FMOD Event Volume和游戏内听到的音量,这三者之间获得一些明确的规律,这个规律会直接影响我下一步的平衡和优化手法。
我当时得到的结论是:
- 两种基本的音乐类型里,样本的基本响度差异大约10-12dB。
- 同一种类型的音乐里,样本平均响度差大约10dB左右。有些背景音乐里,同一条样本的基本动态差(弱音乐部分和高潮部分)也会存在至少10dB的差。
- 语音的峰值和RMS相对比较稳定,但每个大批次的录音很不专业:话筒位置、话放和前级、演员的发声点都存在非常大的区别。有些语音甚至因为后期的不恰当压缩处理,导致房间混响非常明显。
- 技能和动作音效RMS的整体差异(普通肢体动作和技能)平均大约在9dB左右,而有些技能的高频和低频明显过大了。
- 环境声的中频不均匀,有些低频过多(主要基于游戏体验本身做出的判断),音量和频响差异不大,但是很融合上需要更平滑的差异。
因为给我的时间很短,所以第一波动作是优先考虑如何批处理,目标是两个:
- 平衡样本音量、景深和频响,让他们听起来是同一批制作出来的。响度、景深都能达到统一的标准。
- 优化音质,尤其是语音。语音样本色彩显得过于淳朴。
- 衰减所有样本的16kHz以上和60Hz一下频段(不同类别的声音衰减量和频段略有差异)
而天刀里的情况比较复杂,在版本压力下,兜底查了之后理顺显然是不明智的。最现实的办法是充分理解现有机制和它表现出来的音量处理规律,从而得到一个比较快速又安全的解决方案。最终制定的基本音量配置方案如下:
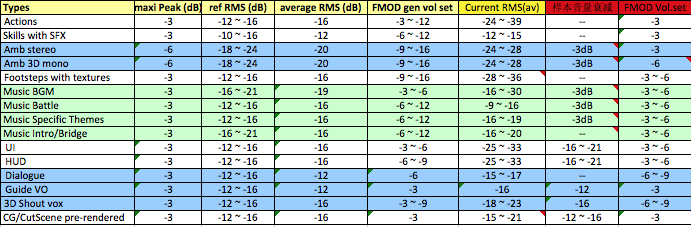
在这份表格里,我列出了当前样本和FMOD的基本音量,也列出了目标音量,以此作为对比。而这份对比,无论对于早期的工作还是后续新增版本的设定,都是具有非常重要的指导意义的。
注:
- 这份表格里的样本音量并不是绝对值,而是通过大量随机抽取样本获得的平均值。
- 这些目标音量和最终游戏里调整后的版本存在一定的出入,但正常情况下,出入范围小于正负3dB。
- 所有这些数值,是在我第一波清理样本RMS和频响优化平衡后得到的(下面会介绍第一波样本平衡的具体手法),而不是在数据没有规律的情况下得到的。其中有些数值的变化量是非常大,例如环境声,和通常的设定存在非常大差异。主要原因在于天刀采用的FMOD版本里,3D音量衰减存在显著的问题:当Event Vol= -6dB的时候,它在游戏里实际表现出的音量衰减大约是-10dB。这个衰减率和SoundMood的设置也有相当大的关系。
- 最后一列的FMOD Vol.Set里,我们可以看到不同层次的声音在FMOD里几乎没有太大的差异。实际上,这现象是很不正常的。根据惯常的做法,样本音量动态差异不大,而FMOD音量设定的动态应该比较大才对。其中主要原因是:很多EVENT采用了multi-layers结构,并且大量采用的用户自定义曲线来实时运算。另一个原因也和上面提到的3D音量衰减率有关。
在这套音量参照系里,我没有采用单机里比较普遍的做法,而是偷懒了的。这套办法并不完美,但是对于天刀这个项目的情况来说,这样的做法无异更实际一些。从不同行的色彩标注里,你也可以看到音量层次设定,简单说,基本上是要样本族群本身的色彩、动态和频响在游戏里形成层次上的差异。
在进行第一波样本优化之前,我做了两件事情:
- 按惯常的音量配比,小规模地找一些常见的声音样本做批处理。主要是:一个地图的音乐和环境声。
- 替换FMOD里的这些样本,随后按预计的惯常音量修改这些音量参数,进游戏里测试其表现情况。我其实在这一步保留了一些重要声音,例如技能,原因在于,我需要保留一些显著的声音在游戏里和这些修改过的声音做对比,看那些新的设定在游戏里究竟会引起怎样的反应。这个手法其实在游戏后期优化的时候也很有效。
所有的第一阶段处理分两步来解决:整体逐类型的先批处理,随后挑出其中比较特殊的一个个单独加工。基本动作都在Soundforge里进行批处理:
- 背景音乐主要采用unltra-funk reverb和EQ来做润色、平衡,让出中频。因为旋律部分主要是中国乐器,而中国乐器主要集中在800-2000Hz中频范围内。这样的动作可以让音乐显得略远,尤其主奏的中国乐器。简单说,所有背景音乐柔化,声场往后靠,声场拉宽,平均RMS达到计划指标,短时(高潮段落)不超过-14dB。这就可以把很大的空间让出来给环境声了。
- 战斗音乐差异比较大,先挑出过大的样本,用EQ来整体衰减,让它们的响度和频响差异听起来不是那么大。然后批处理:加入一些短时混响、用EQ切除中频、衰减中低频。甚至50Hz以下也衰减一些。这就可以让他们把频响空间让出来给技能和动作。平均RMS控制在计划强度上。12kHz以上也大量衰减。(而环境声的12kHz以上则衰减得比较少,这样,环境声的细微颗粒感和空气看就得以显现出来了。)
- 技能统一衰减16kHz(较多)和12kHz(较少),降低刺耳感,少量衰减250和500Hz。随后根据门派技能声音设定的差异,为每个门派的EQ再动一次渲染性的处理,强化门派间的色彩差异。
- 环境声,根据声音本身的特点(例如所有的山谷白天为一类),分别做批处理,统一RMS和频响。随后用混响强化声场宽度和纵深,大风大雨比较靠前(不用或者少用混响渲染),其他都靠后(多一些混响和EQ渲染)。有些样本的16kHz也是衰减非常多,主要是一些知了、蟋蟀和风,甚至这些样本的4kHz也被衰减掉很多,一方面可以让这些声音和其他声音可以平滑融合、不至于显得太突兀,另一方面也是为了获得柔和的听感。
- 语音比较棘手,用传统的EQ、压缩啥都不能解决录音和发声点差异的。采用大染色的插件来做强渲染,让所有语音样本都带有一些同样的音质特点,如此就可以强行让音质差异变小,这个方法是不得已的,也是比较危险的。语音的12kHz高频其实切掉比较多,主要是为了让音质显得更温暖,带有模拟录音的感觉。同时也可以过滤掉中国演员发声上普遍的缺陷:呼吸声和吐字的嘶嘶声。(其实这个问题和话筒选择与摆位也有很大的关系。)
BGM(游戏内非战斗部分的音乐)批处理插件链基本设置:

这些批处理和局部处理的特点:
- 首先,这些插件都带有明显的染色!一方面是因为我的个人喜好,让所有声音都显得比较温暖,另一方面普遍的衰减12kHz以上,会让最终游戏不会出现高频上的明显叠加,并且会比较耐听。而模拟性质的插件可以在高频润色方面做得非常出色(温暖,但不闷闷的)。不用担心最终游戏里高频会损失,游戏的实时混响能够帮你找回这些空气感的高频的。实际上,每个项目可能都需要设定一套渲染性插件的方案,来给这个游戏确定某些统一和明确的色彩。这个色彩会成为整个游戏听觉上的基色。
- 几乎没有多少声音是需要真正全频段的!并且大部分声音在500-1000Hz部分都得到了不同程度的衰减,50和60Hz以下也大量衰减。原因是,大部分声音在这两个频段部分非常容易造成冲突或者叠加(技能大招、爆炸和碰撞声的焦糊频段集中在150-600之间),单个声音的空间变得越来越小。只有当你舍得让每个样本、每一种功能类型的样本都让出特定的空间,一方面可以让这个声音的特征更明确,另一方面也给其他声音让出足够大的空间。
- Ultrafunk Reverb这个插件比较特别,我需要的是一个非常干净、没有明显空间感和染色的混响。最理想的选择是Sonnox Reverb。但是...买不起,所以我选择了这个早就被停产的插件。Ultrafunk插件也是我最喜欢的插件品牌之一,它的Modulator和Delay也是非常棒的,可以广泛用来对手游、尤其是日系那种干净的声音时候。混响在这里,首先不是为了获得某种空间特征,而是为了让音乐和其他声音更好地融合。这种手法在影视和音乐的终混里非常普遍。通常原声唱片里音乐的混响明显比游戏里的音乐混响要干很多,也是这个原因。
- 每次批处理做完,我都要快速随机浏览样本的RMS状况,并且还要用耳朵听一下。同时做一些局部的修改。原因在于:即使两个样本的RMS相同,你听到的声音内容在景声上也可能存在很大的差异,这是我们需要尽量避免的,除非某些样本明确就是为了某种景深上使用的。另外,不同批次制作的样本本身会在频响特征上存在不可预计的差异,也需要在这步骤上解决掉。
3D自然环境声的其中一类样本批处理设置:

以上步骤并不要求这个阶段就让每个声音100%达到最终效果;也不要求这一步100%解决掉所有问题。这一步骤的目标只有一个:确保90-95%的样本能够达到计划的响度和频响平衡就可以。结果是:在游戏里它们可能听起来没有特别的起伏。这也是对的!因为只有这样,你才能明确知道所谓的游戏核心体验与声音之间的感受关系。如果说这一步要做的一个面的工作,那么下一阶段的体验性调整就是点的工作了,只不过“点”很多。而我的步骤是,先解决大的点,随后逐步细化。所谓“大”的点首先是游戏体验、尤其是剧情相关、传送点这样的节点。
批处理框架步骤:
1. 在Soundforge里做好所有需要的插件链:
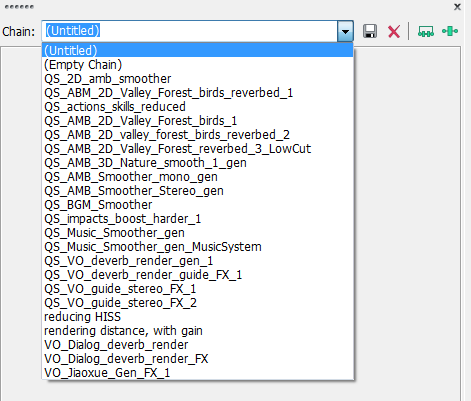
2. 分批处理完之后,保存这些最终使用过的插件链(后缀.bj的文件)
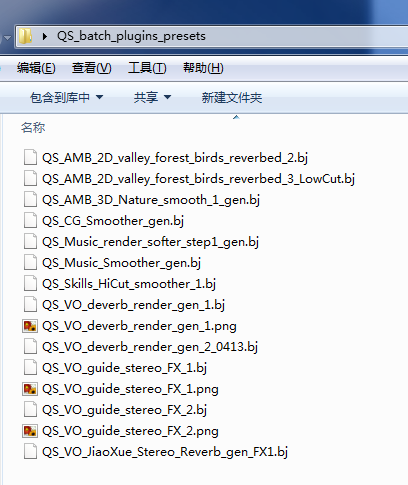
另外还有一些常用的批处理,例如:
*** 这些批处理预设就可以保存在天刀的工作文档内和团队其他成员协作共享,也可以作为重要数据存档,这对于后续内容的添加和处理是至关重要的。
*** 习惯在单个插件里保存项目需要的预设也是个非常好的习惯。
于此同时,所有sound event的音量差异也以0、-3dB、-6dB、-9dB等以3dB为阶梯单位调整(如上图所列)。这个动作的原因来自己心理声学。和预期的结果一样:第二天的版本里,整体音量、响度和动态变化变得就像白开水一样平淡无味,有些地方甚至像是失控了一样。原因在于,之前的Event音量配比做得很细致,已经呈现出凹凸有致的局面了,但是现在的整体平衡显得太有规律。“规律”是非常重要的,因为不同层次的音量差异如果有规律,给予游戏玩家的体验就会更加明确和统一。这一点,可以仔细观察那些美剧,即使做了10季,不同层次的音量比例、频响比例依然如一。对于一个需要迭代的网游或者手游来说,这一点和美剧是完全相同的!现在新的阶梯状音量体系,把这些不同类型声音的层次规律显现了出来,这就是我希望的。而我们第二步要做的就是逐类查找细节,确保某些声音不是太大或者太小,或者在游戏里它需要一些特殊的频段。基本手法也是:先小面积的抽取测试,同时找到两者折衷值,随后批量处理进游戏。这一步也是进一步处理整体平衡和层次。这样做的另一个好处是:让同事也可以轻易听出问题或者看到真正的渲染点。直到这一整体平衡过程结束,我才会开始挑出某些样本进行特别处理。事实上,正如前文提到的,最终绝大部分声音在FMOD里都没有机会设置到-9dB,甚至-6dB的几率都很低,原因在于这个FMOD版本和对于音量的衰减处理存在一些我们完全不知道的算法,我们能够确认的只是-6dB开始,音量衰减速度呈现濒死的体验,这是极其不正常的,但也是短时间内很难花时间去查清楚的。
在以上每一种类型的声音批处理之前,我对每种类型的声音样本作了足够大数量的随机抽取测试,以此找到插件链和渲染参数的折衷配比。并且能够确保后续的任何一批新增内容都能够适用于这些插件链。这步工作绝对是需要经验的,也是非常烧脑的工作。其中最重要的是验证复查工作:RMS响度测试、肉耳听力判断结合。这里需要强调的是:做这个工作,即使对于一个好莱坞高手来说,也是需要每天工作前做一些热身工作的。所谓热身工作就是每天一早去听一下自己最熟悉的音乐或者soundtrack,甚至要听一下前一天处理完的东西,从而确保自己的听力判断体系每天都是一样的。对于有些部分的响度和频响处理工作,我甚至会苛求自己当天必须结束,因为那些声音还会涉及到更多的色彩性问题。稳定的听力判断包括对频响、景深、立体声宽度、色彩,这些判断都不能因为自己的情绪和身体状况而受到影响。稳定的听力判断,的确是需要长期训练的。举个简单的例子,随便找一个高质量的素材库,无论它有多少样本,它们听起来响度、景深、声场宽度等等基本要素都是非常统一的,甚至色彩也是明确统一的。所以,好的监听习惯、稳定明确的口味、足够好的硬件,甚至对插件的理解和运用,都会直接影响到你的判断和结果。这也是为什么行业里都比较推崇拿着录音机出去录素材的做法,不仅仅是为了更好的创作体验等因素,样本的后期清理和优化工作更是一种非常有效的训练。
在处理语音响度和景深的时候,其实遇到过一个非常棘手的问题,也是一个非常典型的问题。我们原计划设想让不同场合出现的对白呈现出不同的景深,需要对样本进行不同的预渲染。例如主线任务B类剧情会比较偏向于融入场景,甚至需要做一些混响预渲染,它们不会出现全频段的样本。而旁白等特殊语音状态则强调贴贴脸特写式的全频段处理。点击语音则显得略微现场感一些,会偏薄,很多频段会被削弱,景深不低于2米。以此就可以呈现出电影化的层次特点,更戏剧性,线条也更清晰。然而,现有的文件命名和角色语音的归类方式,基本上无法让我们可以快速提取出那种分类方式所需要的样本。尤其是语音,因为数量又非常庞大而只能作罢,转而采取简单粗暴的统一渲染办法,最终只能照顾折衷。这个问题也广泛出现在动作和技能方面。如果有机会的看单机的数据,你会发现单机的语音样本名称其实非常长,有些项目里的样本名称甚至会留下录音批次的编号。因为单机还涉及到多语种的问题,所以会更复杂一些。因此可以看出,游戏的平衡和响度控制,往往是一个需要仔细规划的系统工程,从文件结构和文件名称、功能与实施方案等等每个环节都要综合考虑的。
简单介绍一下我在Soundforge里使用的主要插件:
- Waves All(主要是REQ 4, API560 EQ, API2500 compressor, Schopes 730和NR)
- Ultrafunk
- Steinberg Masterting Edition
关于样本响度的主要控制环节:
- 音乐:原作(可用于独立发布出版的),游戏内资源
- 语音:录音(话筒型号与摆位、前级型号与设置、房间声学控制),后期平衡、滤噪与色彩
- 音效:初始素材、游戏内中间阶段素材(整体平衡前)、后期素材(整体平衡后的最终素材)
- 游戏内CG:原作(可用于独立发布出版的),游戏内资源
- 宣传片和宣传歌曲:高精度版本,网络发布版本(低精度格式与CP协调)
尾声
关于响度的问题,我多年前访问Skywalker的时候也请教过那里的制作人和设计师。除了以上提到的那些流程控制外,其实他们对于同一个IP的不同媒介版本,会有截然不同的处理和控制。比方说Star Wars的剧场版在美国主要支持THX,而家庭版则主要有THX、DTS、Dolby AC-3、Doldby Stereo。而宣传片内容,除了以上那些格式外,还有各种数字媒体版本,例如Vimeo、Youtube和 Quicktime,甚至还要考虑iPhone、iTunes之类的。对于不同的播放媒介,他们通常是要重新校准响度和动态的,甚至有时候是终混就要左不同版本,而不是混音完了之后再调整出不同版本。其目的是为了在不同媒介上都能表现出最佳的听感。这个工作目前在EA、UBI之类传统巨头体系里已经很接近影视领域的作法,很多时候宣传片、CG的制作是由专门的团队来完成。如何确保多部门的协作在响度和动态频响上保持一致,确实是一件非常复杂的事情。其中,除了人员的专业训练和工作流程、以及技术标准的普及化认识以外,工具的统一、硬件软件设施的统一也是非常重要的环节。
另外,从项目的一开始就设定一套涉及所有基本声音类型的技术文档,从样本容量、精度到播放方式、载入方式、整合方式都要包含在内。对应的,每种类型的样本频响与动态指标、录音流程、后期流程、批处理流程、命名规则等等,都要有明确的文字和数据记录保存。我们和项目组、CP之间不仅仅存在意识形态和需求上的沟通,更多的还需要足够多的技术沟通,尤其是项目前期阶段。
以上内容供探讨和参考。若有错漏,请斧正,不胜感激!
响度与响度处理经验谈之三部曲:
转载文章请注明出自 Midifan.com
-
2016-11-29
 匿名
虽然我对杨杰这个人的品行很厌恶,但是对于他的技术表示佩服。
匿名
虽然我对杨杰这个人的品行很厌恶,但是对于他的技术表示佩服。 -
2016-11-25
 帛君
最喜欢看杨老师的文章!
帛君
最喜欢看杨老师的文章! -
2016-11-21
匿名
...呵呵
-
2016-11-20
 匿名
不错 赞一下。
匿名
不错 赞一下。 -
2016-11-20 匿名
纯干货啊!杨大师的思想结晶!
