


以后说话可长个心眼吧:Adobe 的 Project VoCo 可以根据你的人声生成你没说过的话
Adobe 公司创新产品用户大会 Adobe MAX 2016 上,Adobe 公司的 Zeyu Jin(显然是个天朝工程师)宣布了 VoCo,一款可以让你如同文本一般编辑口语音频的应用程序。

(原 YouTube 视频链接:https://youtu.be/I3l4XLZ59iw)
VoCo 是针对音频编辑工作的,它可以自动识别出人声语音里的每个单词(目前应该还仅限英文),然后你就可以按照需求剪切和粘贴文本从而改变音频词汇的顺序,而不必去直接编辑波形(请看上面的演示视频,越到后面越精彩)。关键它还有个超赞的地方,它还可以作为一个创作工具,只要 VoCo 对一个人 20 分钟的语音进行分析之后,它就可以直截按新的文本合成这个人声音。就是说你只要被别人捕捉到了至少 20 分钟的演讲,然后这个软件就可以生成你从来没有说过的话,让别人听上去足以以假乱真,以为你真的说过这些话。
虽然还只是在会上演示,过渡的地方还有些不完美,还没有成为正式的产品,但是我们可以想象它的前景,特别是对于配音等工作来说可以成为又一件神器了。甚至一个声优只要被识别出了自己的声音,视频编辑人员就可以直接输入文本让软件来自己说话了。
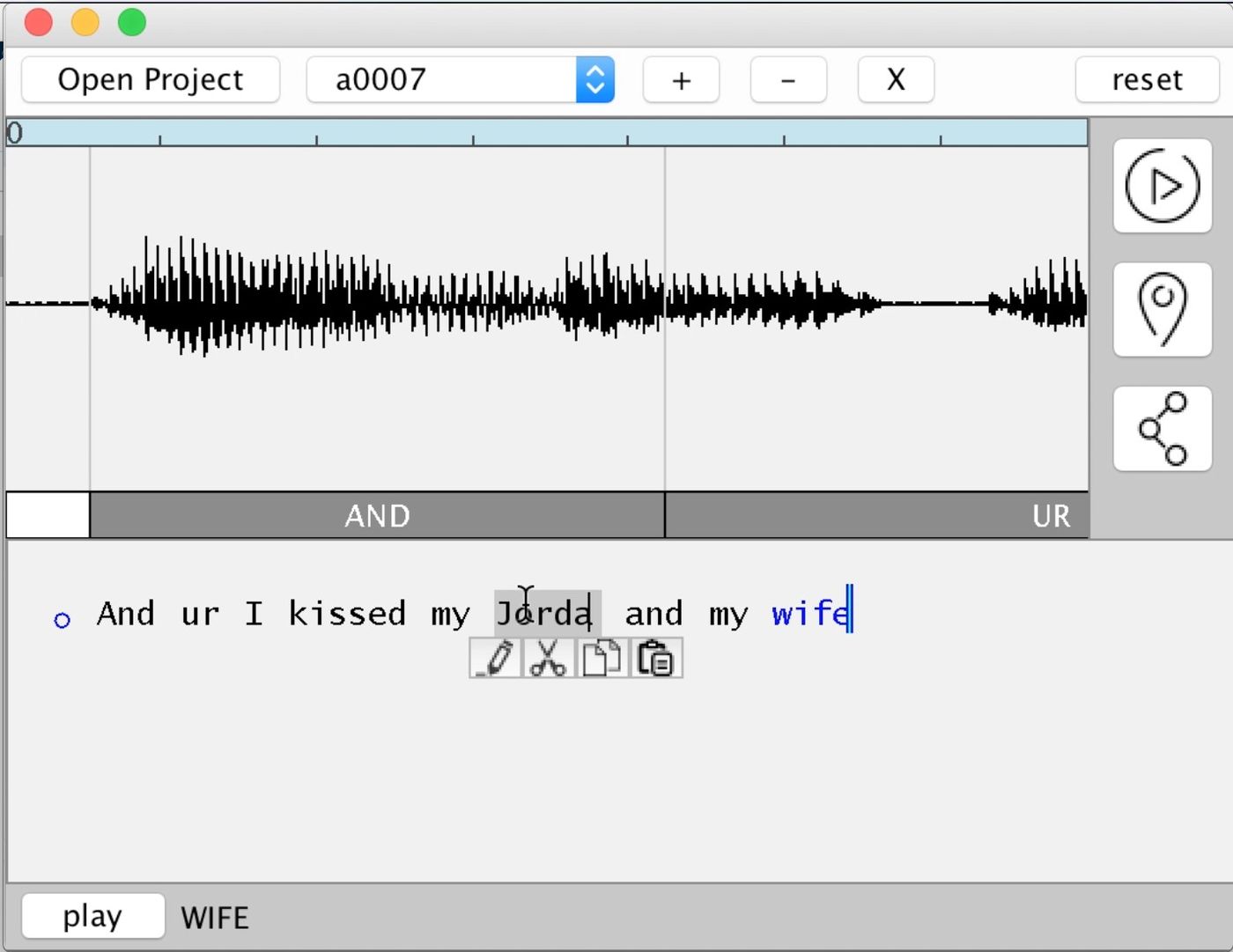
Project VoCo 可以说是秉承了 Adobe 公司的理念,可以看到 VoCo 的这种方式有点像 PS(Photoshop) 一般可以将音频像图像一样分割成单独的元素,甚至可以用现有元素生成新的内容来完成完整的作品。当然如果是单纯的分割元素重新拼接可能容易实现,厉害就厉害在它能根据某人语音进行分析之后直截生成新的音频,也就是直接合成出来。我们推测这就牵扯到很多内容了,音频分析(比如频率,共振峰等),还有机器学习等等。
我们都知道 Yamaha 的 VOCALOID 技术,一提到初音之类的甚至应该是很多人都知道。可以想象一下,如果是 VoCo 这样的技术应用到这个上面是不是可以直接快速开发新的虚拟歌手?甚至个人在家录上一些歌声供分析之后是不是就可以直接做个自己的定制虚拟歌手呢?
另一,日本人最近也开发了一个叫 リアチェンvoice 的产品,它可以实时将你的声音模拟成另据特点的别人的声音,有点类似柯南的实时变声器,可以变成任何一个人的声音。还有 Krotos Dehumaniser 可以将你的声音轻松变成怪兽的声音。这些产品放到一起可能会带来配音行业空前的变革。原谅我的脑洞,我想着以后会有公司开发一个融合了这些技术的产品...
期待 VoCo 能够早日变成成熟产品推向市场。
如今唱歌都可以虚拟歌手直接码字了,是不是以后配音也可以直接码字了...
转载新闻请注明出自 Midifan.com
-
2020-09-12
 匿名
感觉蛮有趣的
匿名
感觉蛮有趣的 -
2016-11-10
匿名
回复 匿名:wow,说的跟真的似的~
-
2016-11-09
 wode
回复 匿名:哦哦,孤陋寡闻了,敢问软件是叫什么,小编去补补脑子
wode
回复 匿名:哦哦,孤陋寡闻了,敢问软件是叫什么,小编去补补脑子 -
2016-11-09
 匿名
小编有所不知啊,美国多年前就有这样的软件啦,不但可以用来说话还可以用来唱歌,比这个软件好用哆啦!只是还未推广。
匿名
小编有所不知啊,美国多年前就有这样的软件啦,不但可以用来说话还可以用来唱歌,比这个软件好用哆啦!只是还未推广。 -
2016-11-09
匿名
好玩好玩呀。

相关产品
相关资源
- 第 133 届 AES 2012 展会视频:Adobe Audition CS6 采访介绍 2012-11-13
- 技术文章:进化还是鸡肋——adobe audition 3 新功能一瞥 2008-01-01
- 技术文章:家有 audition 2.0 初长成 2006-02-11
- audition 2.0 demo版本下载 2006-01-21
- audition 专题论坛 2005-12-01
- audition 系列教学文章 2005-10-17
- audition 1.5 demo版本下载 2005-10-07
Audition (原 Cool Edit Pro) 相关新闻
- 福利:ilikecn 推出全免费的 Adobe Audition CC 2019 中文深度解析视频系列课程
- Adobe Audition CC 再更新,加入自动衰减、智能监听等多项新功能
- Audition CC 2017 快速上手教程(三)贴唱多轨录音、高级编辑和调整
- Audition CC 2017 快速上手教程(二)CD 抓轨、导入视频和单轨录音
- Adobe 发布 Audition CC 2017 更新
- 以后说话可长个心眼吧:Adobe 的 Project VoCo 可以根据你的人声生成你没说过的话
- Adobe 提前透露 Audition CC 2014.1 更新细节
- Adobe Audition CC 2014 现已上市
- AES 展会视频:Adobe Audition CS6 介绍
- Audition 升级到 CS6,开始支持 VST3 插件
- Audition for Mac beta 提供下载试用
- Audition for Mac beta 测试版即将放出
- Adobe 即将移植 Audition 到苹果平台
Adobe 相关新闻
- 评测:用 Adobe AI Audio Enhancer 修复语音
- 福利:Adobe 利用 AI 免费帮你在线增强人声录音,做降噪
- 福利:ilikecn 推出全免费的 Adobe Audition CC 2019 中文深度解析视频系列课程
- Adobe Audition CC 再更新,加入自动衰减、智能监听等多项新功能
- Audition CC 2017 快速上手教程(三)贴唱多轨录音、高级编辑和调整
- Audition CC 2017 快速上手教程(二)CD 抓轨、导入视频和单轨录音
- Adobe 发布 Audition CC 2017 更新
- 以后说话可长个心眼吧:Adobe 的 Project VoCo 可以根据你的人声生成你没说过的话
- Adobe 提前透露 Audition CC 2014.1 更新细节
- Adobe Audition CC 2014 现已上市